





























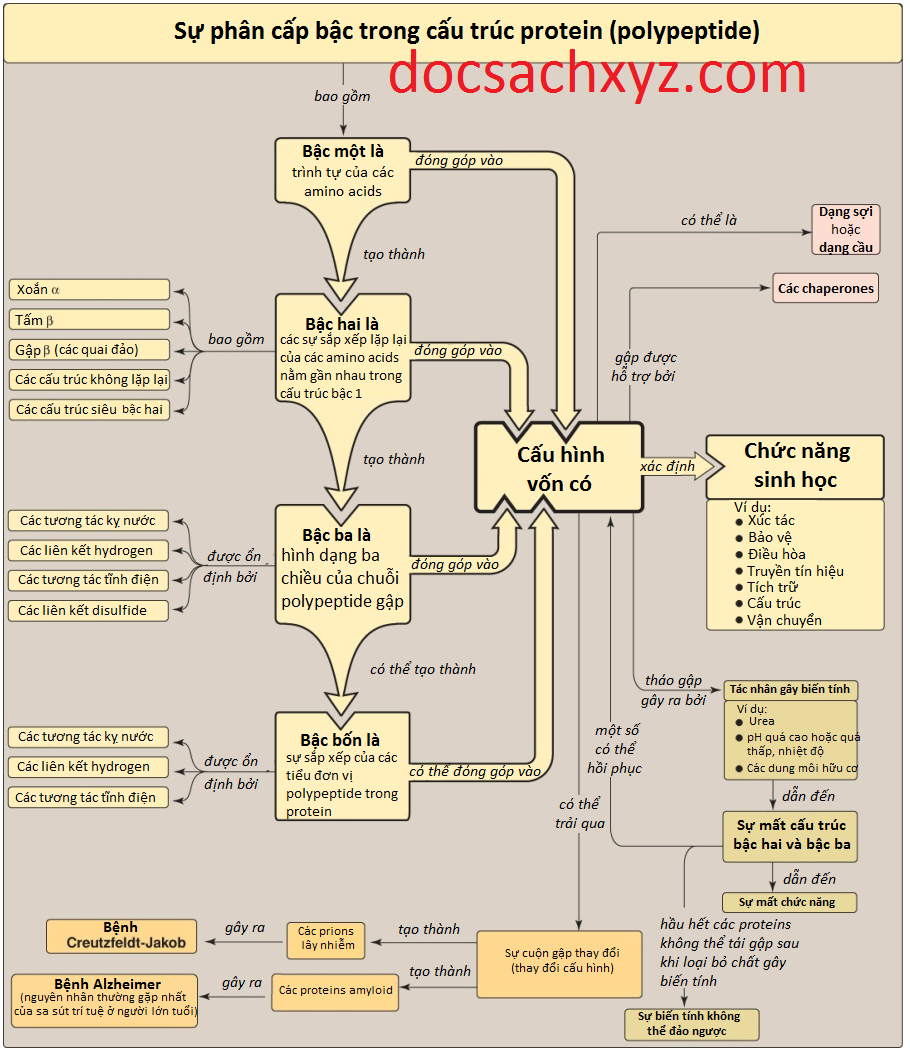
I. Tổng quan
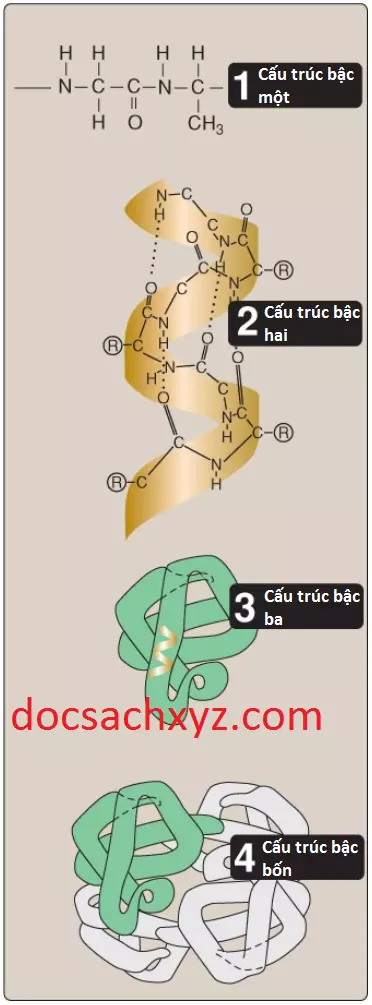
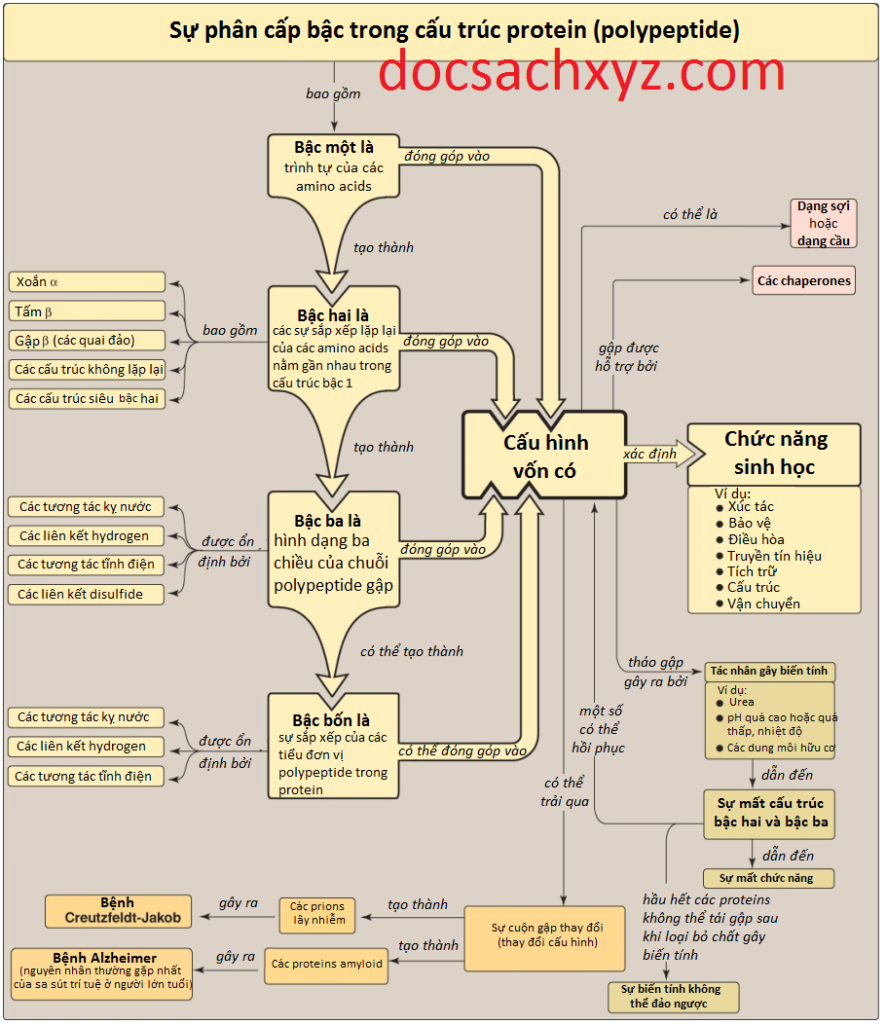
20 amino acids thường tìm thấy trong các proteins được kết hợp lại với nhau bởi các liên kết peptide. Trình tự của các amino acids chứa thông tin cần thiết để tạo ra một phân tử protein với một hình dạng không gian ba chiều duy nhất giúp xác định chức năng. Tính phức tạp của cấu trúc protein sẽ được phân tích tốt nhất bằng cách xem xét phân tử theo 4 cấp độ tổ chức: bậc 1, bậc 2, bậc 3 và bậc 4 (Hình 1). Một sự đánh giá theo bậc tương ứng với sự tăng dần về độ phức tạp cho thấy rằng các thành phần cấu trúc nhất định được lặp lại trong nhiều loại proteins, có nghĩa là có các quy tắc chung về cách mà các proteins đạt được dạng tự nhiên hay chức năng của chúng. Các thành phần cấu trúc lặp lại này thay đổi từ các sự kết hợp đơn giản của xoắn alpha và gập beta tạo nên các cấu trúc đặc trưng (motifs) đến các gấp phức tạp của các miền polypeptide của các proteins đa chức năng.
II. Cấu trúc bậc một
Trình tự đơn thuần của các amino acids trong một phân tử protein được gọi là cấu trúc bậc 1 của protein. Hiểu được cấu trúc bậc 1 của protein thì rất quan trọng bởi vì nhiều bệnh lý di truyền tạo ra các proteins với trình tự amino acid bất thường, điều này gây ra sự gập không phù hợp và mất hoặc giảm chức năng bình thường của proteins. Nếu như các cấu trúc cấp 1 của proteins bình thường và đột biến được đã được biết thì thông tin này có thể được sử dụng để chẩn đoán và nghiên cứu bệnh tật.
A. Liên kết peptide
Trong proteins, các amino acids được kết hợp với nhau bằng các liên kết peptide, là các liên kết amide giữa nhóm alpha-carboxyl của một amino acid với nhóm alpha-amino của một amino acid khác. Ví dụ, valine và alanine có thể hình thành nên dipeptide valylalanine thông qua sự hình thành của một liên kết peptide (Hình 2). Các liên kết peptide thì kháng với các điều kiện làm biến tính các proteins như nhiệt và nồng độ urea cao. Sự tiếp xúc lâu dài với một acid hoặc base mạnh ở nhiệt độ cao là điều kiện cần thiết để bẻ gãy các liên kết này mà không cần tới enzyme.

1. Đặt tên peptide: Theo quy ước, đầu amino tự do (đầu N) của chuỗi peptide được viết sang bên trái và đầu carboxyl tự do (đầu C) sang bên phải. Vì thế, tất cả các trình tự amino acid được đọc từ đầu N- sang đầu C-. Ví dụ, trong Hình 2A, thứ tự của amino acid trong dipeptide là valine , alanine. Liên kết của 50 hoặc nhiều hơn các amino acids thông qua các liên kết peptide, tạo ra một chuỗi không phân nhánh được gọi là polypeptide hay protein. Mỗi amino acid thành phần được gọi là một gốc bởi vì nó là phần amino acid còn lại sau khi các nguyên tử của nước mất đi trong quá trình hình thành liên kết peptide. Khi một peptide được đặt tên thì tất cả các gốc amino acid có các hậu tố riêng (-ine, -an, -ic hay -ate) thay đổi thành -yl, với ngoại lệ cho đầu-C của amino acid. Ví dụ, một tripeptide bao gồm một valine ở đầu N, một glycine và một leucine ở đầu C được gọi là valylglycylleucine.
2. Các đặc điểm của liên kết peptide: Liên kết peptide có đặc điểm liên kết đôi một phần; đó là, nó ngắn hơn so với một liên kết đơn, cứng chắc và phẳng (Hình 2B). Điều này ngăn cản sự xoay tự do quanh liên kết giữa các carbon của nhóm carbonyl và nitrogen của liên kết peptide. Tuy nhiên, các liên kết giữa các alpha-carbons và các nhóm alpha-amino hay alpha-carboxyl có thể xoay tự do (mặc dù chúng bị giới hạn bởi kích thước và đặc điểm của nhóm R). Điều này cho phép chuỗi polypeptide có thể đạt được nhiều cấu hình khác nhau. Liên kết peptide thì hầu như luôn luôn ở cấu hình trans (thay vì cấu hình cis; xem Hình 2B) phần lớn là bởi vì sự can thiệp không gian của các nhóm R (chuỗi bên) khi ở cấu hình cis.
3. Tính phân cực của peptide: Giống như tất cả các liên kết amide, các nhóm -C=O và -NH của liên kết peptide thì không tích điện và chúng cũng không nhận hay giải phóng các protons trong khoảng pH từ 2-12. Vì thế, các nhóm tích điện xuất hiện trong polypeptides chỉ bao gồm nhóm ở đầu N (alpha-amino), nhóm đầu C (alpha-carboxyl) và bất cứ nhóm ion hóa nào xuất hiện trong chuỗi bên của các amino acids thành phần. Tuy nhiên, các nhóm -C=O và -NH của liên kết peptide là phân cực và liên quan với các liên kết hydrogen (ví dụ, trong các xoắn alpha và gập beta).
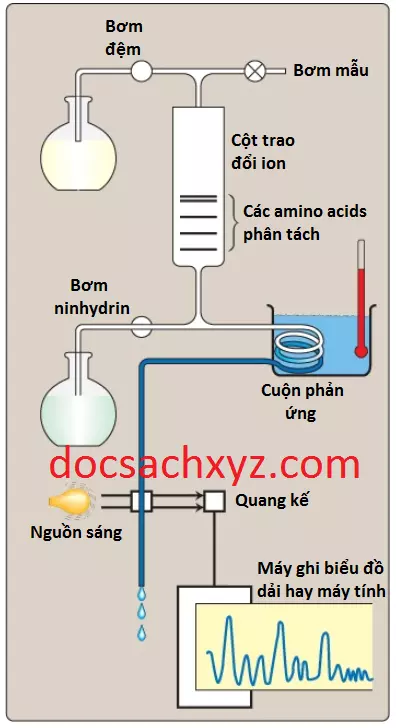
B. Xác định thành phần amino acid của một polypeptide
Bước đầu tiên trong việc xác định cấu trúc cấp một của một polypeptide là xác định và định lượng các amino acids thành phần của nó. Đầu tiên, một mẫu polypeptide thuần được phân tích sẽ được thủy phân bởi acid mạnh để cắt đứt các liên kết peptide và giải phóng ra các amino acids riêng rẽ. Những amino acids này sau đó có thể được phân tách bởi sắc ký trao đổi cation. Các amino acids liên kết với cột sắc ký với các ái tính khác nhau, phụ thuộc vào sự tích điện, tính kị nước và các đặc điểm khác. Mỗi amino acid sau đó được giải phóng một cách lần lượt từ cột sắc ký bằng cách tách rửa bằng các dung dịch tăng cường nồng độ ion và pH (Hình 3) và các amino acids đã phân tách được định lượng bằng quang phổ kế. Sự phân tích mô tả ở trên được thực hiện nhờ sử dụng một máy phân tích amino acid, một máy tự động mà các thành phần của máy được thể hiện trên Hình 3.
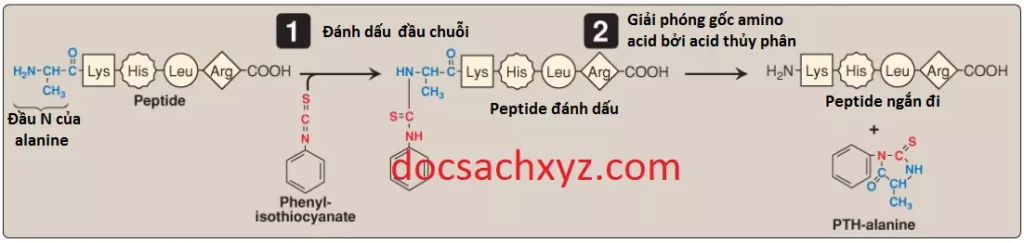
C. Xác định trình tự peptide từ đầu N
Xác định trình tự là một quá trình từng bước một trong việc xác định amino acid đặc hiệu ở từng vị trí trong chuỗi peptide, bắt đầu ở đầu N. Các máy đo trình tự tự động bây giờ đã được sử dụng rộng rãi; quá trình xác định trình tự trong quá khứ bằng việc tạo ra các dẫn xuất amino acid được thể hiện trong Hình 4.
D. Cắt các chuỗi polypeptide thành các phần nhỏ hơn
Nhiều chuỗi polypeptides có cấu trúc bậc 1 chứa hơn 100 amino acids. Những phân tử lớn như thế này thì không thể được xác định trình tự một cách trực tiếp từ đầu này đến đầu kia. Tuy nhiên, những phân tử lớn này có thể được cắt ở những vị trí nhất định và tạo ra các đoạn trình tự nhỏ (Hình 5). Các enzymes mà thủy phân các liên kết peptide được gọi là các peptidases hay proteases. (Chú ý: Exopeptidases cắt ở các đầu của proteins và được phân thành aminopeptidases và carboxypeptidases. Carboxypeptidases được sử dụng trong việc xác định đầu C của amino acid. Endopeptidases giúp cắt ở bên trong một protein).
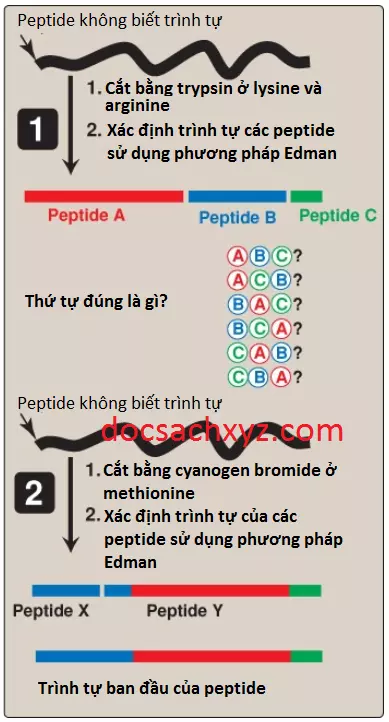
E. Xác định cấu trúc bậc một của một protein bởi trình tự DNA
Trình tự các nucleotides trong một vùng mã hóa proteins của DNA giúp xác định trình tự amino acid của một chuỗi polypeptide. Vì thế, nếu như trình tự nucleotide có thể được xác định thì sự hiểu biết về mã di truyền cho phép trình tự các nucleotide có thể được dịch mã thành trình tự amino acid tương ứng của chuỗi polypeptide đó. Quá trình gián tiếp này mặc dù sử dụng thường xuyên để thu được trình tự amino acid của proteins nhưng có các giới hạn về việc không tiên đoán được các vị trí của các liên kết disulfide trong chuỗi gập và không thể xác định được có bất kỳ amino acids nào được chỉnh sửa sau sự sáp nhập của nó vào trong chuỗi polypeptide (chỉnh sửa sau dịch mã). Vì thế, xác định trình tự protein trực tiếp là một công cụ cực kỳ quan trọng để xác định chính xác đặc điểm của trình tự bậc 1 của nhiều chuỗi polypeptides.
III. Cấu trúc bậc hai
Trục polypeptide thì không có một cấu trúc không gian ba chiều ngẫu nhiên, mà thay vào đó, nhìn chung là nó sẽ hình thành nên các sự sắp xếp đều đặn lặp lại của các amino acids nằm gần nhau trong trình tự chuỗi. Những sự sắp xếp đều đặn này được gọi là cấu trúc bậc hai của chuỗi polypeptide. Xoắn alpha, tấm beta, và gập beta (hay quai beta) là các ví dụ về các cấu trúc bậc hai thường gặp trong các protein. Mỗi cấu trúc trong số này được ổn định bởi các liên kết hydrogen giữa các nguyên tử của trục peptide.
A. Xoắn alpha
Một số xoắn khác của chuỗi polypeptide được tìm thấy trong tự nhiên nhưng xoắn alpha là thường gặp nhất. Nó là một cấu trúc xoắn ốc phải, vững chắc, bao gồm lõi trục polypeptide cuộn, nén chặt, với các chuỗi bên của các L-amino acids thành phần mở ra bên ngoài từ trục trung tâm để tránh sự can thiệp về mặt không gian với nhau (Hình 6). Một nhóm các proteins rất phong phú có chứa xoắn alpha. Ví dụ, keratins là một họ proteins dạng sợi vững chắc, có liên quan gần mà cấu trúc của nó thì gần như toàn bộ là xoắn alpha. Chúng là thành phần chủ yếu của các mô như tóc và da. Ngược lại với keratin, cấu trúc của myoglobin thì cũng chứa nhiều xoắn alpha nhưng là một phân tử hình cầu, linh động được tìm thấy trong các cơ.
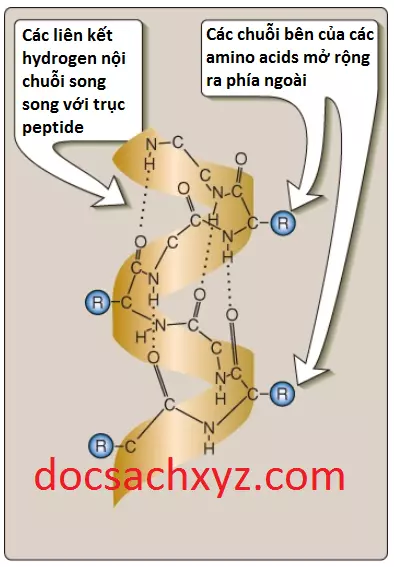
1. Liên kết hydrogen: Một xoắn alpha được ổn định nhờ liên kết hydrogen phong phú giữa nguyên tử oxygen thuộc nhóm carbonyl của liên kết peptide và nguyên tử hydrogen của amide, đều là các phần của trục polypeptide (xem Hình 6). Các liên kết hydrogen mở rộng lên và song song với xoắn từ nguyên tử oxygen thuộc carbonyl của một liên kết peptide đến nhóm -NH của liên kết peptide thuộc gốc amino acid thứ 4 tính từ nguyên tử oxygen vừa mới nói đến. Điều này giúp đảm bảo rằng tất cả các thành phần liên kết peptide (không tính các thành phần liên kết peptide đầu tiên và cuối cùng) được liên kết với nhau thông quan các liên kết hydrogen nội chuỗi. Các liên kết hydrogen riêng lẻ thì rất yếu, nhưng khi chúng khi đóng vai trò cùng nhau sẽ giúp ổn định xoắn.
2. Các amino acid mỗi chu kỳ xoắn: Mỗi chu kỳ của một xoắn alpha chứa 3.6 amino acids. Vì thế, các amino acids cách nhau 3 đến 4 gốc trong chuỗi cấp 1 thì sẽ gần nhau về mặt không gian khi được gập lại trong xoắn alpha.
3. Các amino acids làm phá vỡ cấu trúc xoắn alpha: Nhóm R của một amino acid xác định xu hướng của nó trong xoắn alpha. Proline làm phá vỡ cấu trúc xoắn alpha bởi vì nhóm amino bậc hai vững chắc của nó thì không tương tích về mặt cấu hình với xoắn bên phải của xoắn alpha. Thay vào đó, nó tạo ra một trở ngại liên kết can thiệp vào cấu trúc xoắn đang đều đặn của chuỗi. Glycine, với nhóm R là hydrogen, có tính linh động cao. Ngoài ra, các amino acids với các nhóm R tích điện hay “cồng kềnh” lần lượt như glutamate và tryptophan, và những amino acids có nhánh ở beta-carbon, carbon đầu tiên trong nhóm R (như valine) thì dường như đều không được tìm thấy trong xoắn alpha.
B. Tấm beta
Tấm beta là một dạng khác của cấu trúc bậc hai mà trong đó tất cả các thành phần liên kết peptide đều liên quan đến liên kết hydrogen (Hình 7A). Bởi vì các bề mặt của các tấm beta thì gập hay hình thành nên dạng “xếp” nên chúng thường được gọi là các tấm gập beta. Sự gập này là do các alpha-carbon kế tiếp thì hơi phía trên hoặc bên dưới mặt phẳng của tấm. Các minh họa cấu trúc protein thường biểu diễn các chuỗi beta dưới dạng các hình mũi tên rộng (Hình 7B).
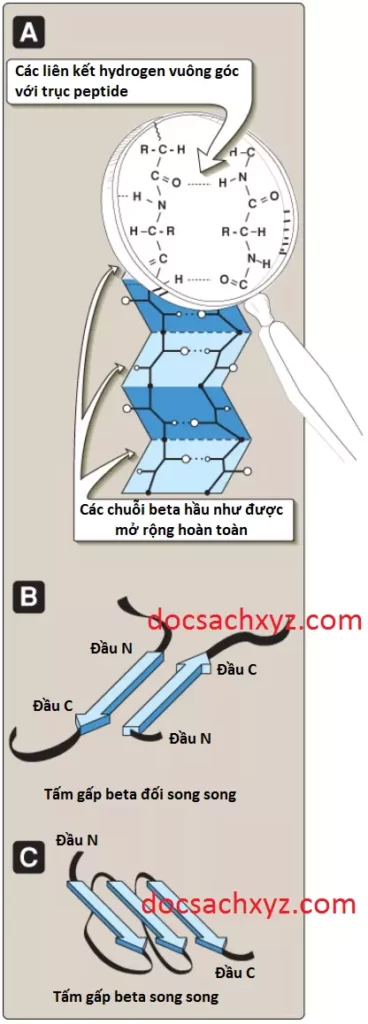
1. Sự hình thành: Một tấm beta được hình thành bởi 2 hoặc nhiều chuỗi peptide (các chuỗi beta) được sắp xếp thẳng ở 2 bên và được ổn định bởi các liên kết hydrogen giữa các nhóm carboxyl và amino của các amino acids mà cách xa nhau trong một chuỗi polypeptide đơn (các liên kết nội chuỗi) hoặc trong các chuỗi polypeptide khác nhau (các liên kết gian chuỗi). Các chuỗi beta kế cận được sắp xếp thep kiểu đối song song với nhau (với đầu tận N khác phía như trong Hình 7B) hoặc song song với nhau (với đầu tận N ở cùng phía như trong Hình 7C). Trên mỗi chuỗi beta, các nhóm R của các amino acid kế cận sẽ mở theo các hướng đối diện, phía trên và phía dưới mặt phẳng của tấm beta. Các tấm beta thì không phẳng và vặn xoắn bên phải khi nhìn dọc theo trục polypeptide.
2. So sánh các xoắn alpha với các tấm beta: Trong các tấm beta, các chuỗi beta thì hầu như được mở ra hoàn toàn và các liên kết hydrogen giữa các chuỗi thì vuông góc với trục polypeptide (xem Hình 7A). Ngược lại, trong các xoắn alpha thì chuỗi polypeptide bị cuộn xoắn lại và các liên kết hydrogen sẽ song song với trục polypeptide (xem Hình 6).
Định hướng của các nhóm R của các gốc amino acid trong cả xoắn alpha và tấm beta đều có thể tạo ra sự hình thành của các bên phân cực và không phân cực trong những cấu trúc bậc hai này, bằng cách đó làm cho chúng trở thành chất lưỡng vùng.
C. Các gấp beta
Các gập beta còn được gọi là các quai ngược và các quai beta, làm đảo hướng của chuỗi polypeptide, giúp nó hình thành nên một cấu trúc hình cầu đặc. Chúng thường được tìm thấy trên bề mặt của các phân tử protein và thường bao gồm các gốc tích điện. Các gập beta có tên này là bởi vì chúng thường kết nối các chuỗi kế tiếp của các tấm beta đối song song. Chúng thường bao gồm 4 amino acids, một trong số đó có thể là proline, amino acid mà gây ra một sự gián đoạn trong chuỗi polypeptide. Glycine, amino acid có nhóm R nhỏ nhất, thường được tìm thấy trong các gập beta. Các gập beta được ổn định bởi sự thành của các liên kết hydrogen giữa gốc đầu và gốc cuối trong gập.
D. Cấu trúc bậc hai không lặp lại
Gần một nửa của một protein hình cầu trung bình được tổ chức thành các cấu trúc lặp lại, như xoắn alpha và tấm beta. Phần còn lại của chuỗi polypeptide thì được mô tả là có một cấu hình quai hoặc cuộn xoắn. Những cấu trúc bậc hai không lặp lại này thì không phải là cấu trúc ngẫu nhiên mà đơn giản là có ít cấu trúc lặp lại hơn so với các cấu trúc đã mô tả ở trên. Thuật ngữ “cuộn xoắn ngẫu nhiên” là để đề cập đến cấu trúc rối loạn thu được khi các proteins bị biến tính.
E. Các cấu trúc siêu bậc hai (motifs)
Các protein hình cầu được cấu trúc bởi các thành phần cấu trúc bậc 2 kết hợp lại bao gồm các xoắn alpha, các tấm beta, và các cuộn xoắn, tạo thành các cấu hình đặc trưng hay gọi là motifs. Những motifs này hình thành chủ yếu vùng lõi (vùng bên trong) của phân tử. Chúng được kết nối bởi các vùng quai (như các gập beta) ở bề mặt của protein. Các cấu trúc siêu bậc hai thường được tạo ra bởi sự xếp khít của các chuỗi bên từ các thành phần cấu trúc bậc hai lân cận. Ví dụ, các xoắn alpha và các tấm beta kế cận nhau trong trình tự amino acid cũng thường (nhưng không phải luôn luôn) nằm kế cận nhau trong protein cuộn gập cuối cùng. Một số motifs thường gặp được minh họa trong Hình 8.
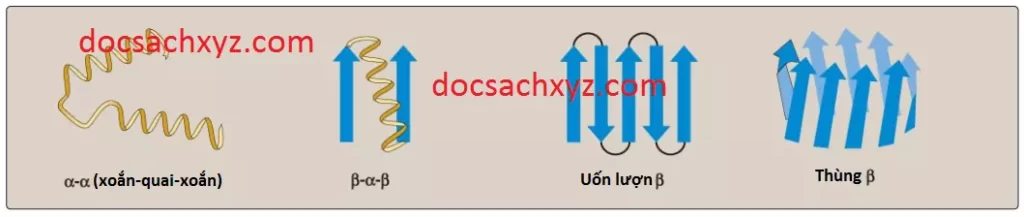
Các motifs có thể liên quan đến các chức năng nhất định. Các proteins mà liên kết với DNA chứa một số lượng giới hạn các motifs. Motif xoắn-quai-xoắn là một ví dụ được tìm thấy trong một số protein đóng vai trò là các yếu tố phiên mã.
IV. Cấu trúc bậc ba
Cấu trúc bậc 1 của một chuỗi polypeptide giúp xác định cấu trúc bậc 3 của nó. Thuật ngữ “bậc 3” là đề cập đến cả sự gấp của các miền (domains) (các đơn vị cấu trúc và chức năng cơ bản) và sự sắp xếp cuối cùng của các miền trong chuỗi polypeptide. Cấu trúc bậc ba của các protein hình cầu trong dung dịch nước thì sẽ đặc với trọng lượng cao (xếp chặt) của các nguyên tử trong lõi của phân tử. Các chuỗi bên kỵ nước được vùi ở phía bên trong, ngược lại các nhóm ưa nước thường được tìm thấy trên bề mặt của phân tử.
A. Các miền (domains)
Các miền là các đơn vị cấu trúc ba chiều và chức năng nền tảng của các chuỗi polypeptide. Các chuỗi polypeptide mà có nhiều hơn 200 amino acids thì thường bao gồm hai hoặc nhiều miền. Lõi của một miền thì được tạo ra từ các sự kết hợp của các thành phần cấu trúc siêu bậc hai (motifs). Sự gấp của chuỗi peptide bên trong một miền thường xảy ra một cách độc lập so với sự gấp trong các miền khác. Vì thế, mỗi miền sẽ có các đặc điểm của một protein hình cầu nhỏ, đặc mà độc lập về mặt cấu trúc so với các miền khác trong chuỗi polypeptide.
B. Các tương tác ổn định
Cấu trúc ba chiều đặc trưng của mỗi polypeptide được xác định bởi trình tự amino acid của nó. Các tương tác giữa các chuỗi bên của các amino acid giúp định hình sự cuộn gập của chuỗi polypeptide để hình thành nên một cấu trúc đặc. Bốn loại tương tác sau đây sẽ phối hợp với nhau trong việc làm ổn định các cấu trúc bậc ba của các protein hình cầu.
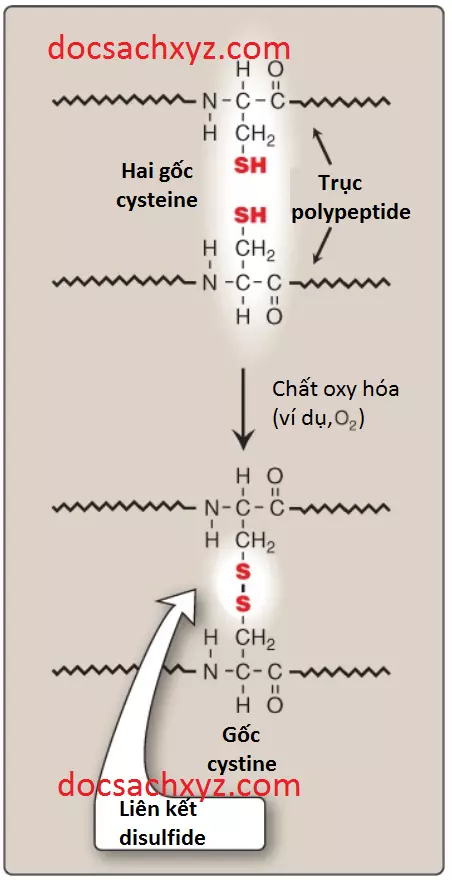
1. Liên kết disulfide: Một liên kết disulfide (-S-S-) là một liên kết cộng hóa trị được hình thành từ nhóm sulfhydryl (-SH) của mỗi 2 gốc cysteine để tạo ra một gốc cystine (Hình 9). Hai cysteins có thể được phân tách khỏi nhau bởi nhiều amino acids trong trình tự cấp một của một chuỗi polypeptide hay thậm chí có thể nằm trên 2 chuỗi polypeptide khác nhau. Sự cuộn gập của các chuỗi polypeptide làm cho các gốc cysteine gần lại và cho phép liên kết cộng hóa trị của các chuỗi bên của chúng. Một liên kết disulfide sẽ đóng góp vào sự ổn định của hình dạng không gian ba chiều của phân tử protein và ngăn cản nó bị biến tính trong môi trường ngoại bào. Ví dụ, nhiều liên kết disulfide được tìm thấy bên trong các protein như immunoglobulins được tiết bởi các tế bào. Nên lưu ý rằng protein disulfide isomerase sẽ giúp cắt đứt và hình thành lại các liên kết disulfide trong suốt quá trình cuộn gập.
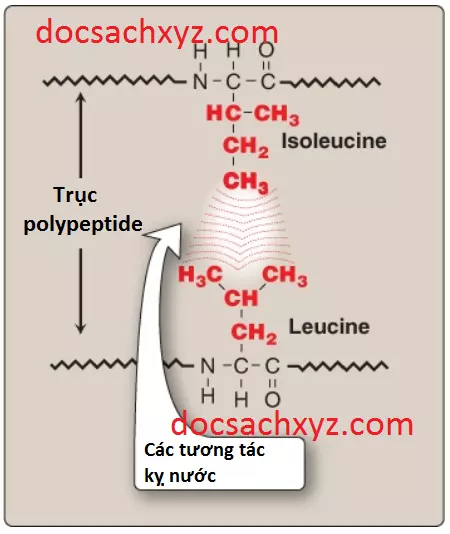
2. Các tương tác kỵ nước: Các amino acids có các chuỗi bên không phân cực có khuynh hướng nằm bên trong phân tử polypeptide, nơi mà chúng liên kết với các amino acid kỵ nước khác (Hình 10). Ngược lại, các amino acids với các chuỗi bên phân cực hoặc tích điện có khuynh hướng nằm trên bề mặt của phân tử, tiếp xúc với dung môi phân cực. Trong mỗi trường hợp, sự phân tách các nhóm R diễn ra thuận lợi nhất về mặt năng lượng.
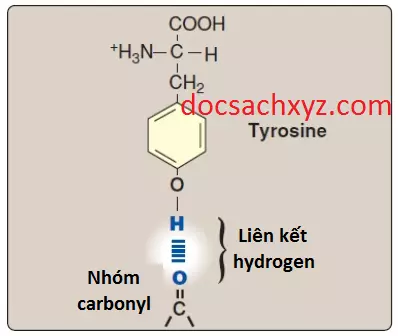
3. Các liên kết hydrogen: Các chuỗi bên của amino acid chứa các nguyên tử hydrogen liên kết với oxygen hoặc nitrogen như trong các nhóm rượu của serine và threonine, có thể hình thành nên các liên kết hydrogen với các nguyên tử giàu electron như oxygen của nhóm carboxyl hay nhóm carbonyl của một liên kết peptide (Hình 11; xem thêm Hình 12). Sự hình thành các liên kết hydrogen giữa các nhóm phân cực trên bề mặt của các protein và dung môi nước làm tăng cường tính tan của protein.
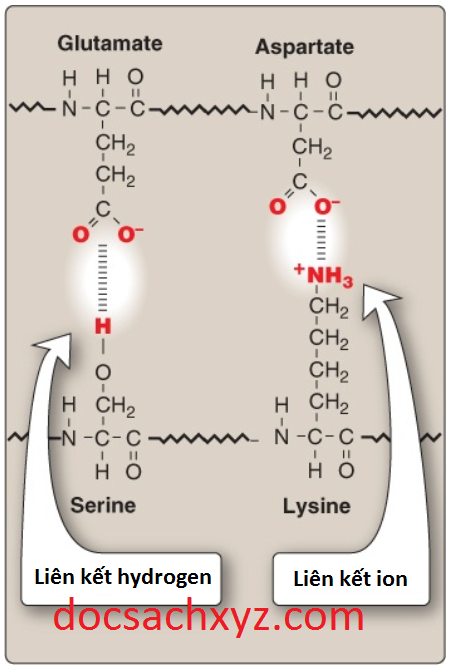
4. Các tương tác ion: Các nhóm tích điện âm, như nhóm carboxylate (-COO–) trong chuỗi bên của aspartate hay glutamate, có thể tương tác với các nhóm tích điện dương như nhóm amino (-NH3+) trong chuỗi bên của lysine (xem Hình 11).
C. Sự gập của protein
Các tương tác giữa các chuỗi bên của các amino acids giúp xác định cách một chuỗi polypeptide thẳng gấp thành hình dạng ba chiều phức tạp của protein chức năng. Sự gập của proteins, xảy ra bên trong tế bào trong vài giây đến vài phút liên quan đến các con đường có trật tự và không phải ngẫu nhiên. Khi một peptide gập lại, các dạng cấu trúc bậc hai hình thành, được điều khiển bởi hiệu ứng kỵ nước nên các nhóm kỵ nước đến gần nhau khi gặp nước. Những cấu trúc nhỏ này kết hợp lại để hình thành nên các cấu trúc lớn hơn. Các sự kiện tiếp theo giúp ổn định cấu trúc bậc hai và khởi động sự hình thành cấu trúc bậc ba. Trong giai đoạn cuối cùng, peptide đạt được trạng thái gập hoàn toàn, dạng tự nhiên (dạng chức năng) được đặc trưng bởi một trạng thái năng lượng thấp (Hình 13). Một số protein hoạt động về mặt sinh học hay các thành phần của chúng thiếu đi một cấu trúc bậc ba ổn định và được xem là các proteins rối loạn về bản chất.
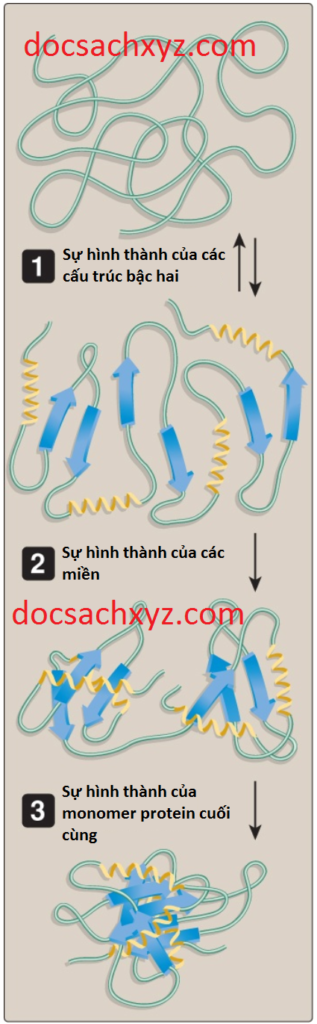
D. Sự biến tính của protein
Sự biến tính là do sự tháo gấp và sự rối loạn tổ chức của các cấu trúc cấp hai và cấp ba mà không có sự thủy phân của các liên kết peptide. Các chất gây biến tính bao gồm nhiệt, urea, các dung môi hữu cơ, các acids hoặc bases mạnh, các chất tẩy rửa và các ion kim loại nặng như chì. Sự biến tính, dưới các điều kiện lý tưởng, có thể đảo ngược được như khi protein tái gập thành cấu trúc vốn có ban đầu của nó khi chất biến tính bị loại bỏ đi. Tuy nhiên, hầu hết các proteins vẫn sẽ bị rối loạn vĩnh viễn một khi bị biến tính. Các protein biến tính thì thường không tan và kết tủa khỏi dung dịch.
E. Chaperones trong sự gập protein
Thông tin cần cho sự cuộn gập protein chính xác thì được chứa bên trong cấu trúc bậc một của chuỗi polypeptide. Tuy nhiên, hầu hết các protein biến tính thì sẽ không hồi phục cấu hình vốn có ngay cả dưới các điều kiện môi trường thuận lợi. Điều này là bởi vì đối với nhiều protein, sự gập là một quá trình cần sự thủy phân của ATP và một nhóm các protein đặc hiệu, được gọi là chaperones của phân tử. Chaperones còn được gọi là các protein shock nhiệt (HSPs), tương tác với một chuỗi polypeptide ở các giai đoạn khác nhau trong suốt quá trình gập. Một số chaperones liên kết với các vùng kỵ nước của một chuỗi polypeptide đang mở rộng và quan trọng trong việc giữ protein không bị gập cho đến khi sự tổng hợp của nó được hoàn thành (như Hsp70). Các chaperones khác hình thành nên các cấu trúc đại phân tử dạng lồng bao gồm 2 vòng xếp chồng. Proteins được gập một phần đi vào trong lồng, liên kết với khoang trung tâm qua các tương tác kỵ nước, cuộn gập và được giải phóng (như Hsp60 của ty thể).
Chaperones sau đó tạo điều kiện cho sự gập protein chính xác bằng cách liên kết với và ổn định các vùng kỵ nước có khuynh hướng kết tụ lộ ra trong các chuỗi polypeptide mới tạo ra và bị biến tính, ngăn cản sự gập sớm.
V. Cấu trúc bậc bốn
Trong khi nhiều proteins chứa một chuỗi polypeptide đơn và được gọi là các proteins đơn thể, các proteins khác bao gồm hai hoặc nhiều chuỗi polypeptide mà có thể tương tự về mặt cấu trúc hoặc hoàn toàn không liên quan. Sự sắp xếp của các tiểu đơn vị polypeptide này là cấu trúc bậc bốn của protein. Các tiểu đơn vị được tổ chức với nhau chủ yếu bởi các tương tác không phải cộng hóa trị bao gồm các liên kết hydrogen , các liên kết ion và các tương tác kỵ nước. Các tiểu đơn vị có thể thực hiện chức năng một cách độc lập với nhau hoặc có thể hoạt động phối hợp, như trong hemoglobin, trong đó sự liên kết của oxygen với một tiểu đơn vị của hemoglobin sẽ làm tăng ái lực của các tiểu đơn vị khác đối với oxygen.
Các isoforms của các proteins nhất định tất cả đều thực hiện cùng một chức năng nhưng có các cấu trúc bậc một khác nhau. Chúng có thể có nguồn gốc từ các gen khác nhau hoặc từ sự xử lý đặc hiệu mô sản phẩm của một gen duy nhất. Nếu như các protein hoạt động như là các enzymes thì chúng được gọi là các isoenzymes.
VI. Sự gập sai của protein
Sự gập protein là một quá trình phức tạp mà đôi khi có thể tạo ra các phân tử cuộn gập không phù hợp. Những proteins gập sai này thường được đánh dấu và thoái hóa bên trong tế bào. Tuy nhiên, chất lượng của hệ thống kiểm soát này thì không hoàn hảo và các thành phần nội bào và ngoại bào của các proteins cuộn gập sai có thể tập trung lại, đặc biệt là khi con người già đi. Sự kết tụ các proteins cuộn gập sai thì liên quan với nhiều bệnh tật.
A. Các bệnh amyloid
Sự cuộn gập sai của các proteins có thể xảy ra một cách tự phát hoặc có thể được gây ra bởi một đột biến trong một gen nhất định, sau đó, tạo ra proteins thay đổi. Ngoài ra, một số protein đang bình thường, sau sự phân cắt bất thường của enzyme phân cắt protein, có thể thu được một cấu hình dị thường mà sẽ dẫn đến sự hình thành tự phát của các thành phần protein dạng sợi chứa các cấu hình dạng tấm gập beta. Sự tích tự những thành phần protein dạng sợi không tan này, được gọi là amyloids, có tác động lên các rối loạn thoái hóa thần kinh như bệnh Alzheimer và bệnh Parkinson.
Thành phần chủ yếu của mảng amyloid mà tích tụ trong bệnh Alzheimer là amyloid beta (Abeta), một peptide ngoại bào chứa 40 đến 42 amino acid với một cấu trúc bậc hai là tấm gấp beta trong các vi sợi không phân nhánh. Peptide này, khi kết tập thành một cấu hình tấm gập beta, sẽ độc hại đối với thần kinh và là sự kiện bệnh lý chính yếu dẫn đến đặc điểm suy giảm nhận thức của bệnh. Abeta mà tích tụ bên trong não trong bệnh Alzheimer thì được tạo ra từ các quá trình cắt bởi enzyme (bởi secretases) từ các protein tiền thân của amyloid lớn hơn, là một protein xuyên màng đơn xuất hiện trên bề mặt tế bào trong não và các mô khác (Hình 14).
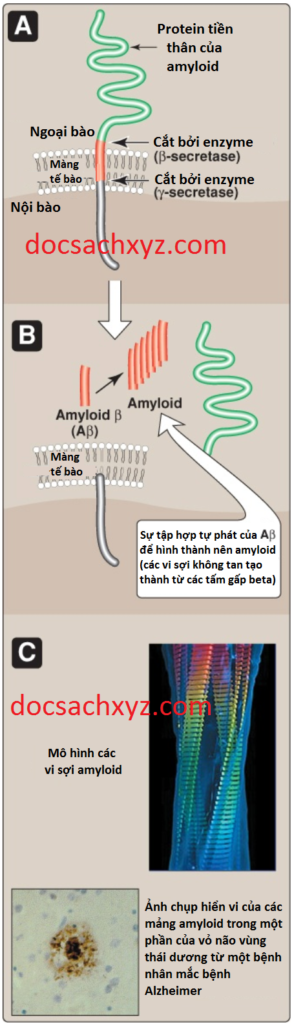
Các thành phần peptide Abeta, tạo ra amyloid được tìm thấy trong nhu mô não và quanh các mạch máu. Hầu hết các trường hợp của bệnh Alzheimer thì không có tính chất di truyền, mặc dù ít nhất 5% trường hợp là có tính chất gia đình. Một yếu tố sinh học thứ hai có liên quan đến sự phát triển của bệnh Alzheimer là sự tích tụ của các đám rối tơ thần kinh bên trong các tế bào thần kinh. Một thành phần quan trọng của những đám rối tơ thần kinh này là một dạng bất thường của tau protein (τ), bị phosphoryl hóa quá mức và không tan; ở phiên bản khỏe mạnh, τ giúp lắp ráp và ổn định cấu trúc vi ống. Protein τ khiếm khuyết xuất hiện làm chặn các hoạt động của phiên bản bình thường của loại protein này. Trong bệnh Parkinson, amyloid được hình thành từ protein alpha-synuclein.
B. Các bệnh prion
Prions hay tạm gọi là các hạt truyền nhiễm protein thì có liên quan đến một số bệnh nhất định. Protein prion (PrP) là tác nhân có thể gây ra các bệnh nhũn não truyền nhiễm (transmissible spongiform encephalopathies (TSEs)) bao gồm bệnh Creutzfeldt-Jakob ở người, bệnh Scrapie ở cừu và bệnh não xốp bò, thường gọi là “bệnh bò điên”, trên gia súc. Tính lây nhiễm của tác nhân gây ra bệnh Scrapie ở cừu thì liên quan đến một chủng protein đơn mà không tạo phức với nucleic acid. Protein lây nhiễm này thì được gọi là PrPSc (Sc = Scrapie). Nó có kháng tính cao với sự thoái hóa của các enzyme phân giải protein và có khuynh hướng hình thành nên các thành phần vi sợi không tan, tương tự như amyloid được tìm thấy trong một số bệnh khác của não. Một dạng không lây nhiễm là PrPC (C = cellular), được mã hóa bởi cùng gen với tác nhân lây nhiễm, xuất hiện ở não động vật có vú bình thường trên bề mặt của các tế bào thần kinh và các tế bào thần kinh đệm. Vì thế, PrPC là một protein vật chủ. Không có sự khác nhau trong cấu trúc hay có sự chỉnh sửa sau dịch mã nào được tìm thấy giữa các dạng bình thường và lây nhiễm của protein. Điểm then chốt làm cho protein trở nên lây nhiễm rõ ràng là nằm ở các sự thay đổi trong cấu hình không gian ba chiều của PrPC. Nghiên cứu cho thấy rằng một số lượng các xoắn alpha xuất hiện trong PrPC không lây nhiễm được thay thế bởi các tấm beta ở dạng lây nhiễm (Hình 15). Sự khác biệt về mặt cấu hình này có lẽ đã tạo ra sự kháng tương đối với sự thoái hóa của các enzyme phân giải protein đối với các prions lây nhiễm và cho phép phân biệt được chúng với các PrPC bình thường trong mô nhiễm. Các tác nhân lây nhiễm vì thế sẽ là một phiên bản bị biến đổi của một protein bình thường, đóng vai trò như là một khuôn mẫu cho sự chuyển đổi protein bình thường thành cấu hình gây bệnh. Các TSEs thì luôn luôn gây tử vong và không có phương pháp điều trị nào hiện nay mà có thể thay đổi kết cục này.
VII. Tổng hợp bài viết
- Một cấu hình vốn có của protein là cấu trúc protein gập hoàn toàn có thể thực hiện chức năng (Hình 16).
- Cấu trúc 3 chiều duy nhất của một protein thì được xác định bởi cấu trúc bậc một của nó, hay trình tự các amino acids .
- Các tương tác giữa các chuỗi bên của amino acid giúp điều hướng sự gập lại của chuỗi polypeptide để hình thành nên các cấu trúc bậc hai, bậc ba và đôi khi bậc bốn, phối hợp trong việc ổn định cấu hình vốn có của protein.
- Một nhóm các protein chuyên biệt có tên là chaperones thì cần cho sự gập phù hợp của nhiều chủng proteins.
- Sự biến tính của protein gây ra sự tháo gập và rối loạn tổ chức của cấu trúc protein, không kèm theo sự thủy phân các liên kết peptide.
- Bệnh tật có thể xảy ra khi protein bình thường sở hữu một cấu hình gây độc tế bào, như trong trường hợp của bệnh Alzheimer (AD) và các bệnh nhũn não lây nhiễm (TSEs), bao gồm bệnh Creutzfeldt-Jakob.
- Ở bệnh Alzheimer, các proteins bình thường, sau quá trình xử lý hóa học bất thường, sẽ nhận một trạng thái cấu hình dị thường và sẽ dẫn đến sự hình thành của các thành phần beta peptide amyloid (Abeta) gây độc thần kinh chứa các cấu trúc dạng tấm gập beta. Trong TSEs, các tác nhân lây nhiễm là một phiên bản biến đổi của một protein prion bình thường và đóng vai trò như là một khuôn mẫu cho sự chuyển protein bình thường thành cấu hình gây bệnh.
Các bạn có thể xem bài viết mới trên Facebook tại đây: https://www.facebook.com/profile.php?id=61550892771585
Các bạn có thể xem bài viết trước tại đây: https://docsachxyz.com/cac-amino-acids-va-vai-tro-cua-ph/
Cảm ơn các bạn đã theo dõi bài viết. Hẹn gặp lại các bạn trong các bài viết tiếp theo nhé !!!







{kind=link}